In this post we focus on __m256, which contains 8 single precision floats.
1.Blend
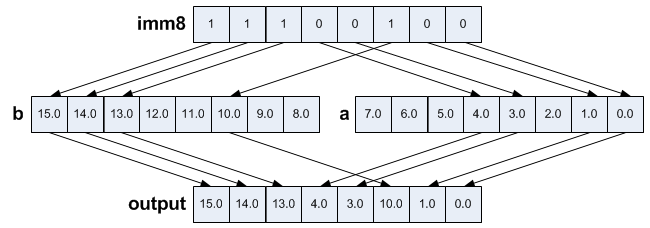
Blend two vectors to form a new one. _mm256_blendv_ps() has the same functionality but is slower.
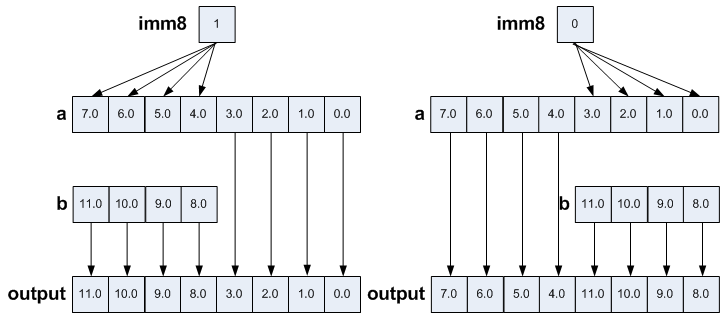
output = _mm256_blend_ps(a, b, 0b11100100);
2.Broadcast
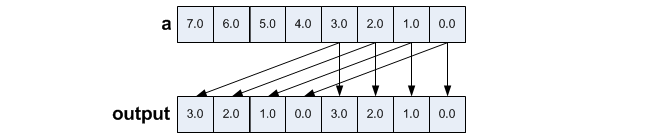
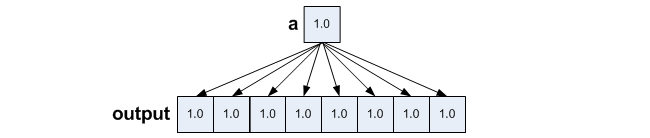
Broadcast either 128 bits or 32 bits from memory to the entire 256 bits container. _mm256_broadcastss_ps() is also used to broadcast 32 bits but is slower.
output = _mm256_broadcast_ps((__m128*)&a);
output = _mm256_broadcast_ss((float*)&a[1]);
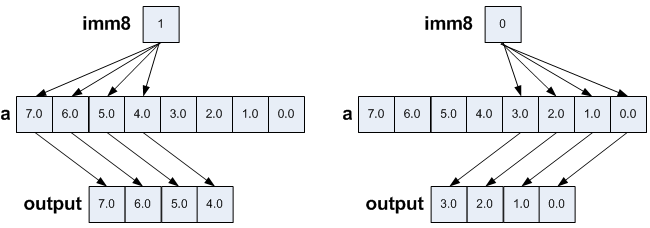
To broadcast 64 bits, use _mm256_broadcast_sd().
3.Extract & Insert
Extract/insert 128 bits from/into the vector.
output = _mm256_extractf128_ps(a, 1);
output = _mm256_insertf128_ps(a, b, 1);
4.Permute
Shuffle data inside the vector. _mm256_permute_ps() is faster but can only shuflle data inside each 128-bit lane while on the other hand, _mm256_permutevar8x32_ps() is slower but can shuffle data in a very flexible manner.
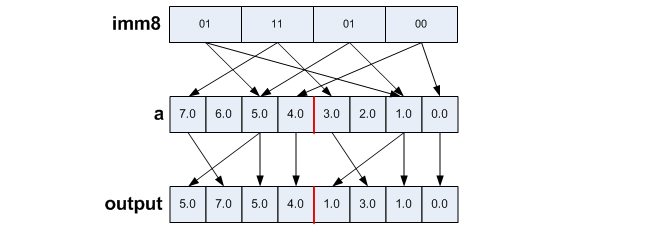
output = _mm256_permute_ps(a, 0b01110100);
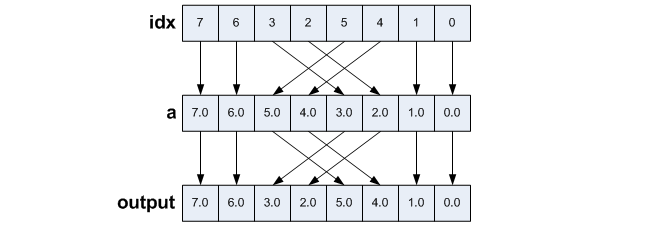
output = _mm256_permutevar8x32_ps(a, idx);
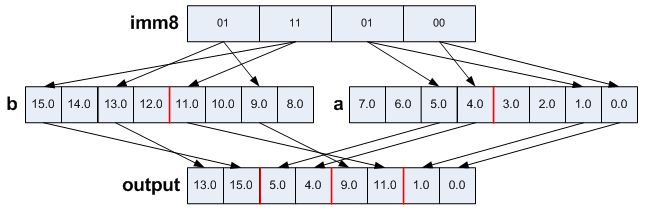
5.Permute2 & Shuffle
Shuffle data between two vectors. _mm256_permute2f128_ps can also be used to switch the high/low 128 bits if a and b are the same vector.
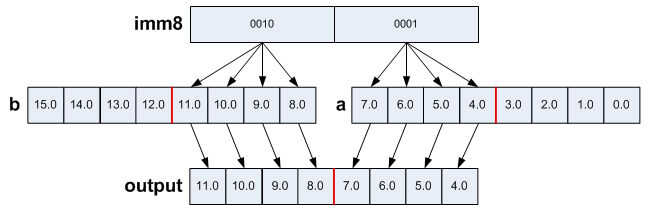
output = _mm256_permute2f128_ps(a, b, 0b00100001);
output = _mm256_shuffle_ps(a, b, 0b01110100);
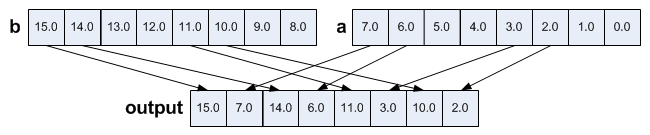
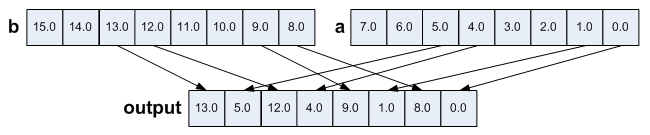
6.Unpack
Unpack and interleave elements from the high/low half of each 128-bit lane from two vectors.
output = _mm256_unpackhi_ps(a, b);
output = _mm256_unpacklo_ps(a, b);
Appendix. Latency & Throughput on Haswell
See this post to understand the terms latency & throughput.
It should be pointed out that manipulating data across the high/low 128 bits causes higher latency and should be avoided if possible.
| Architecture | Latency | Throughput |
|---|---|---|
| _mm256_blend_ps() | 1 | 0.33 |
| _mm256_broadcast_ps() | 1 | - |
| _mm256_broadcast_ss() | - | - |
| _mm256_extractf128_ps() | 1 | 1 |
| _mm256_insertf128_ps() | 3 | - |
| _mm256_permute_ps() | 1 | - |
| _mm256_permutevar8x32_ps() | 3 | 1 |
| _mm256_permute2f128_ps() | 3 | 1 |
| _mm256_shuffle_ps() | 1 | 1 |
| _mm256_unpackhi_ps() | 1 | 1 |
| _mm256_unpacklo_ps() | 1 | 1 |
References
[1] Intel Intrinsic Guide (https://software.intel.com/sites/landingpage/IntrinsicsGuide/)